Our paper that sets a new world record
Paper (Link)
Our paper titled “Semi-supervised Classification of Malware Families Under Extreme Class Imbalance via Hierarchical Non-Negative Matrix Factorization with Automatic Model Determination” has been accepted to the ACM Transactions on Privacy and Security (TOPS) (formerly known as TISSEC) journal. This paper introduces an innovative method that represents a significant breakthrough in the field of Windows PE malware classification. For the first time, our approach achieves realistic and robust malware family classification by leveraging selective classification, specifically, the reject-option. Realistic in this context entails the ability to perform classification under extreme class imbalances, encompassing both rare and prevalent malware types. Additionally, our method excels in detecting novel malware families while maintaining high performance even as the percentage of labeled malware specimens decreases. To the best of our knowledge, our paper sets a new world record by simultaneously classifying an unprecedented number of malware families, surpassing prior work by a factor of 29. This achievement underscores the groundbreaking nature of our approach. In summary, this paper addresses several critical shortcomings in the domain of large-scale malware analysis through machine learning, making significant advancements in the classification of Windows PE malware and paving the way for enhanced cybersecurity measures.
Abstract:
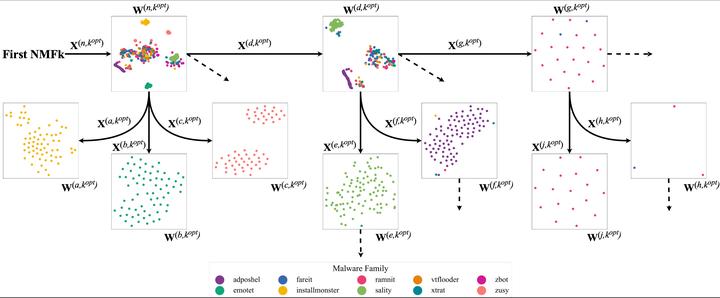
Identification of the family to which a malware specimen belongs is essential in understanding the behavior of the malware and developing mitigation strategies. Solutions proposed by prior work, however, are often not practicable due to the lack of realistic evaluation factors. These factors include learning under class imbalance, the ability to identify new malware, and the cost of production-quality labeled data. In practice, deployed models face prominent, rare, and new malware families. At the same time, obtaining a large quantity of up-to-date labeled malware for training a model can be expensive. In this paper, we address these problems and propose a novel hierarchical semi-supervised algorithm, which we call the HNMFk Classifier, that can be used in the early stages of the malware family labeling process. Our method is based on non-negative matrix factorization with automatic model selection, that is, with an estimation of the number of clusters. With HNMFk Classifier, we exploit the hierarchical structure of the malware data together with a semi-supervised setup, which enables us to classify malware families under conditions of extreme class imbalance. Our solution can perform abstaining predictions, or rejection option, which yields promising results in the identification of novel malware families and helps with maintaining the performance of the model when a low quantity of labeled data is used. We perform bulk classification of nearly 2,900 both rare and prominent malware families, through static analysis, using nearly 388,000 samples from the EMBER-2018 corpus. In our experiments, we surpass both supervised and semi-supervised baseline models with an F1 score of 0.80.
Maksim E. Eren
Scientist
Maksim E. Eren is a Scientist at Los Alamos National Laboratory, specializing in machine learning and artificial intelligence for large-scale data science applications.